「RでPISA2015」というエントリーで、いくつかのWeb記事に触発されて、OECDという国際機関が3年間隔で行なっている国際学力調査「PISA」の2015年実施データを、統計向けプログラミング言語「R」を使って触り始めたことを書きました。
R言語の基礎知識が無いまま、サンプルを見様見真似でデータファイルの読み込みからグラフの描画までやってみましたが、まだまだ未完成状態でした。
その後、R言語のリファレンス書籍を購入した上で、さらにプログラムを修正し、思い描いていたグラフを一通り描けるところまで辿り着きました。
—
作成中気になっていたことの一つとして、PISA2015データを日本語で扱うための情報が、明石書店発行のPISA正規報告書(有償)しかないことがあります。
PISA2015関連の情報については、「PISA2015関連」(ICTのある学び)にまとめておきましたが、日本語版を作成して調査協力をした国立教育政策研究所のWebページでさえ報道機関向けレベルの公表資料が掲載されているだけで、PISAに関する正規の日本語情報は明石書店が契約して発行している日本語版報告書くらいしかありません。
そのため、背景指標を得る質問調査(ICT活用調査を含む)の日本語は、販売されている報告書を手に入れないと知ることができません。いくつかのWeb記事で分析・紹介されている調査結果の質問や回答の文章は、OECDがWebサイトで無償公開している英語版報告書を各自で翻訳している状態です。
PISAの趣旨や目的からすれば、調査結果をもとに各国の教育政策に関する議論が様々に誘発されることが大事であるにも関わらず、日本の場合、どうしても日本語要約された報道発表範囲の限られた話題しか扱われず、それ以外は英語原文か有償の日本語版報告書を得なければならない壁があります。
今回のように調査の生データを処理して視覚化する際も、質問文や回答選択肢文を日本語で表示した方が圧倒的に理解がしやすいわけですが、そのためのリソースはネット上に存在しません。
日本語によるPISA調査作業量の大変さとそれを担われている関係者の労力には敬意を持ちますし、それを踏まえて発行される日本語報告書が有償販売されることは理解できます。ただ、もう少し社会的な議論が進むよう無償部分の情報流通量を増やす努力も必要かなと思います。
少なくとも調査データを自前で処理する際に使えるリソースは欲しいものです。
—
そこで、プログラム処理する際に使えるようPISA2015における「国別コードと国名」「ICT活用調査の質問文」「ICT活用調査の回答選択肢文」をcsvファイルにしておきました。
国別コードと国名
(csv)http://www.edufolder.jp/files/pisa2015/ISO3166_pisa.csv
(xlsx)http://www.edufolder.jp/files/pisa2015/ISO3166_pisa.xlsx
ICT活用調査の質問文
(csv)http://www.edufolder.jp/files/pisa2015/pisa2015_ICT_Familiarity_Questionnaire.csv
(xlsx)http://www.edufolder.jp/files/pisa2015/pisa2015_ICT_Familiarity_Questionnaire.xlsx
ICT活用調査の回答選択肢文
(csv)http://www.edufolder.jp/files/pisa2015/pisa2015_ICT_Familiarity_Questionnaire_answercode.csv
(xlsx)http://www.edufolder.jp/files/pisa2015/pisa2015_ICT_Familiarity_Questionnaire_answercode.xlsx
(csv形式の方は)UTF-8コードで日本語も含めてありますので、英文と日本文を切り替えて利用するのにも便利です。データ構造の解説は今回省略します(ごめんなさい)。
(修正20170116:「〜」を「-」に修正し,xlsx形式も用意しました。)
ちなみに,OECDが用意しているコード表は「Codebooks for the main files」としてダウンロードページに用意されています。これの日本語版があったらいいのになという感じです。
—
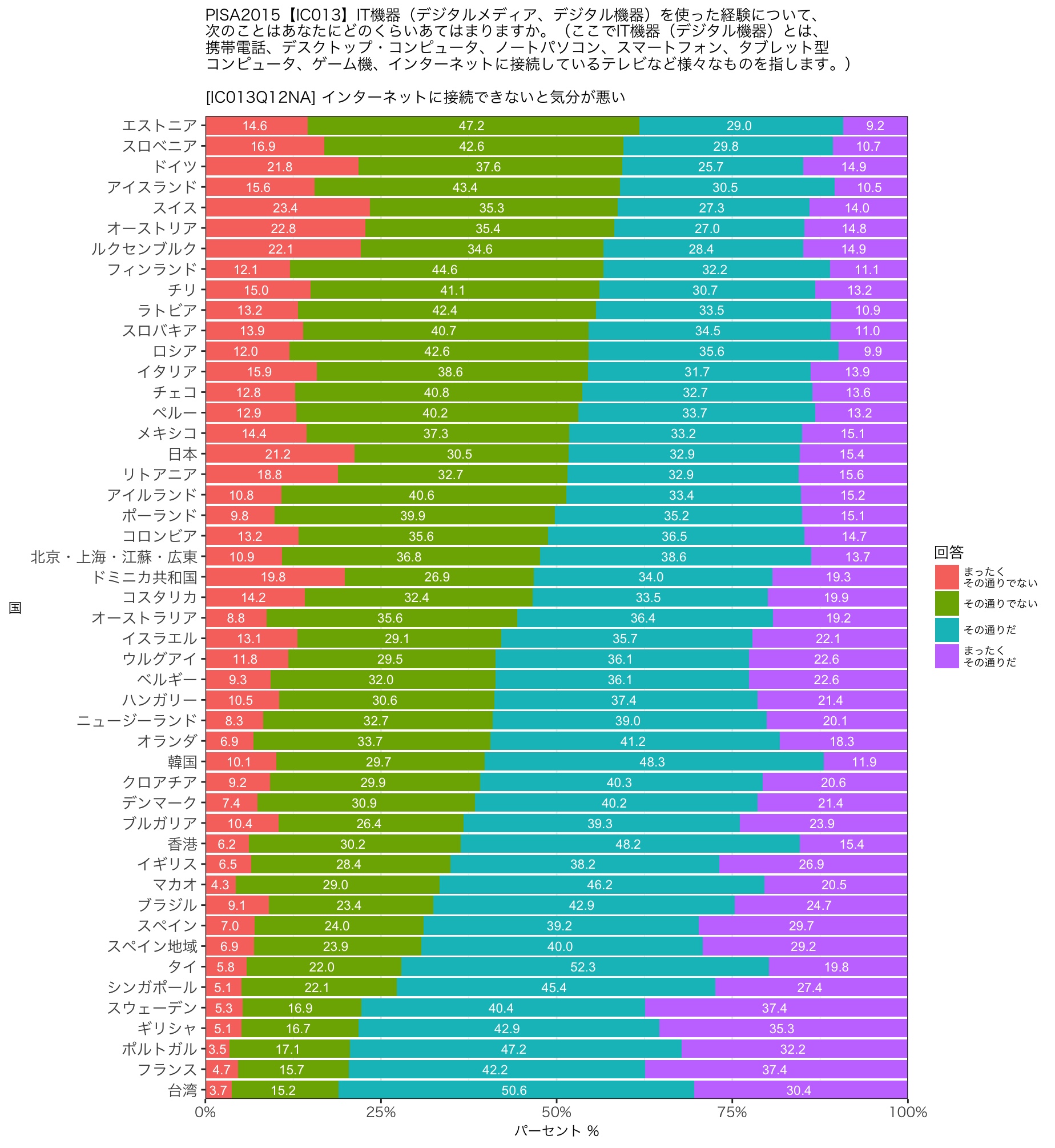
上記のデータファイルを利用したプログラムを作成してみました。質問番号(と表示順序)を設定したら半自動でグラフが出力されるところまで動くようになったと思います。
設定した質問についてグラフ化するR言語ソースコードは以下が現在の進捗です。今回はファイルやライブラリの読み込み(Base部分)と質問ごとに集計してグラフ描画する部分(ICT部分)を分けてみました。Base部分は最初の一回だけ実行すれば、あとは読込み済みのデータで処理できます。
(追記20170114:macOSでの導入を前提としたスクリプトのため,Windows等の他環境では,日本語フォント指定の部分等について改変する必要あり。)
# For PISA2015 Base (※最新のものが下方のリンクに有り)
# K.RIN
library(readr)
library(haven)
library(ggplot2)
library(plyr)
library(tidyverse)
question_items <- read_csv("pisa2015_ICT_Familiarity_Questionnaire.csv", col_names = TRUE, col_types = list(col_character(), col_character(), col_character()))
answer_items <- read_csv("pisa2015_ICT_Familiarity_Questionnaire_answercode.csv", col_names = TRUE, col_types = list(.default = col_character(), items_count = col_character()))
country_code <- read_csv("ISO3166_pisa.csv", col_names = TRUE, col_types = list(col_character(), col_character(), col_character(), col_character()))
student_raw <- read_sav("Cy6_ms_cmb_stu_qqq.sav")
school_raw <- read_sav("Cy6_ms_cmb_sch_qqq.sav")
pisa2015_base.R (←こちらの方が最新版)
# For PISA2015 ICT (※最新のものが下方のリンクに有り)
# K.RIN
#
# ★設定項目
# ・質問ID(「selected_question = " "」の部分)
# ・表示順序の組合わせ(「mutate('list_order' = `1`)」の部分)
#★質問番号
selected_question = "IC010Q09NA"
selected_question_big = substring(selected_question, 1,5)
#質問文読込
q_title <- paste(question_items$questions_ja[grep(selected_question_big, question_items$questions_no, value = FALSE, fixed = FALSE)][[1]])
#質問文整形
q_width = 39
q_title_disp <- character()
q_title_length <- nchar(q_title)
for(i in 1:q_title_length%/%q_width+1) {
q_title_disp[i] <- paste(substring(q_title, ((i-1)*q_width+1), ((i-1)*q_width+1)+(q_width-1)), '\n')
}
q_title_disp[i+1] <- paste("\n", selected_question,"\n", question_items$questions_ja[grep(selected_question, question_items$questions_no)])
q_title_all <- paste(q_title_disp, collapse="")
#回答選択肢読込
ans_item_count <- as.integer(answer_items$items_count[grep(selected_question, answer_items$questions_no)])
ans_item_colcount <- as.integer(answer_items$items_count[grep(selected_question_big, answer_items$questions_no)][1])
#回答選択肢設定
ans_limits <- as.character(answer_items[grep(selected_question_big, answer_items$questions_no),][1,3:sum(ans_item_count+2)])
ans_labels <- as.character(answer_items[grep(selected_question, answer_items$questions_no),][1,sum(ans_item_colcount+3):sum(ans_item_colcount+ans_item_count+2)])
#ラベル
y_label <- "パーセント %"
x_label <- "国"
legend_label <- "回答"
#回答データ抽出
stu_tmp <- subset(student_raw, student_raw[[selected_question]] != "NaN")
#scl_tmp <- subset(school_raw, school_raw$[[selected_question]] != "NaN")
country_ans_table <- table(stu_tmp[["CNT"]],stu_tmp[[selected_question]])
#縦長dfへ変換
country_ans_long <- as_tibble(country_ans_table,validate = FALSE)
colnames(country_ans_long) <- c("CNT", "answer", "count")
#横長df版クロス表
country_ans_wide <- spread(country_ans_long, answer, count)
#★表示順序用対象項目設定(回答の場合) `1`+`2`
country_ans_wide <- country_ans_wide %>% rownames_to_column('num') %>% mutate('list_order' = `1`)
#文字から数値にモード変換
mode(country_ans_wide$id) <- "integer"
#国名変換
country_ans_wide <- ddply(country_ans_wide, 'CNT', transform, country_name = country_code$Name_ja[grep(CNT, country_code$Alpha3)])
#表示順序用対処数値設定(ナンバリングの場合)
#country_ans_wide <- ddply(country_ans_wide, num, transform, list_order = num * -1)
#ラベルが"X1"などになった場合も想定して…
colnames(country_ans_wide) <- c("num", "CNT", ans_limits, "list_order", "country_name")
#国名付き縦長df
country_ans_long <- gather(country_ans_wide, answer,count,-num,-CNT,-list_order,-country_name)
#並べ替え
country_ans_long <- arrange(country_ans_long, desc(CNT), desc(answer))
#列名変更
colnames(country_ans_long) <- c("num", "CNT", "list_order","country_name","answer", "count")
#パーセント計算(描画計算用)
country_ict <- ddply(country_ans_long, "CNT", transform, percent = count / sum(count) * 100, 0.1)
#小数点以下1桁処理(表示用)
country_ict <- ddply(country_ict, "CNT", transform, percent_rounded = round_any(count / sum(count) * 100, 0.1))
#リスト順序(パーセント計算)
country_ict <- ddply(country_ict, "CNT", transform, list_percent_order = round_any(list_order / sum(count) * 100, 0.1))
#ラベル位置計算
country_ict <- ddply(country_ict, "CNT", transform, percent_label_y = cumsum(percent)-0.5*percent)
country_ict <- arrange(country_ict, CNT, desc(answer))
#フォントファミリー設定(macOS用)
quartzFonts(HiraKaku = quartzFont(rep("HiraginoSans-W3", 4)))
par(family = "HiraKaku")
#グラフ描画
graph <- ggplot(country_ict, aes(x = reorder(country_name, list_percent_order), y = percent, fill = factor(answer))) +
ggtitle(sprintf("%s", q_title_all)) +
ylab(y_label) +
xlab(x_label) +
labs(fill = legend_label) +
coord_flip(expand = FALSE) +
geom_bar(stat = "identity", position='stack') +
geom_text(aes(y = percent_label_y,
label = paste(format(percent_rounded, nsmall = 1),"")), color = "white", size = 3) +
scale_y_reverse(breaks = c(100.0,75.0,50.0,25.0,0.0),
labels = c("0%","25%","50%","75%","100%")) +
scale_fill_discrete(limits = ans_limits, labels = ans_labels) +
scale_color_manual(values = rainbow(7)) +
theme_bw() +
theme(plot.margin = margin(1, 1, 1, 1, "cm"),
plot.title = element_text(family = "HiraKaku", size = 10),
plot.caption = element_text(family = "HiraKaku", size = 10),
legend.title = element_text(family = "HiraKaku", size = 10),
legend.text = element_text(family = "HiraKaku", size = 7),
axis.title = element_text(family = "HiraKaku", size = 9),
axis.title.y = element_text(angle = 0, vjust = 0.5),
axis.text.x = element_text(family = "HiraKaku", size = 9),
axis.text.y = element_text(family = "HiraKaku", size = 10))
print(graph)
#ggsave("pisa2015_graph.png", graph)
pisa2015_ict.R (←こちらの方が最新版)