
この年末年始は帰省をしつつ,原稿執筆をしていました。
プログラミング体験・学習に関する原稿でしたが,他と違った角度から照らしたものにしようと悪戦苦闘してました。詳しくはまた機会をあらためて書こうと思います。
—
締切仕事から解放されて,ようやく画像生成系のAIを自分のパソコン環境に導入してみました。
この記事のアイキャッチ画像はその画像生成AIモデルの一つである「Anything-v4.0」を導入して描画させたものです。
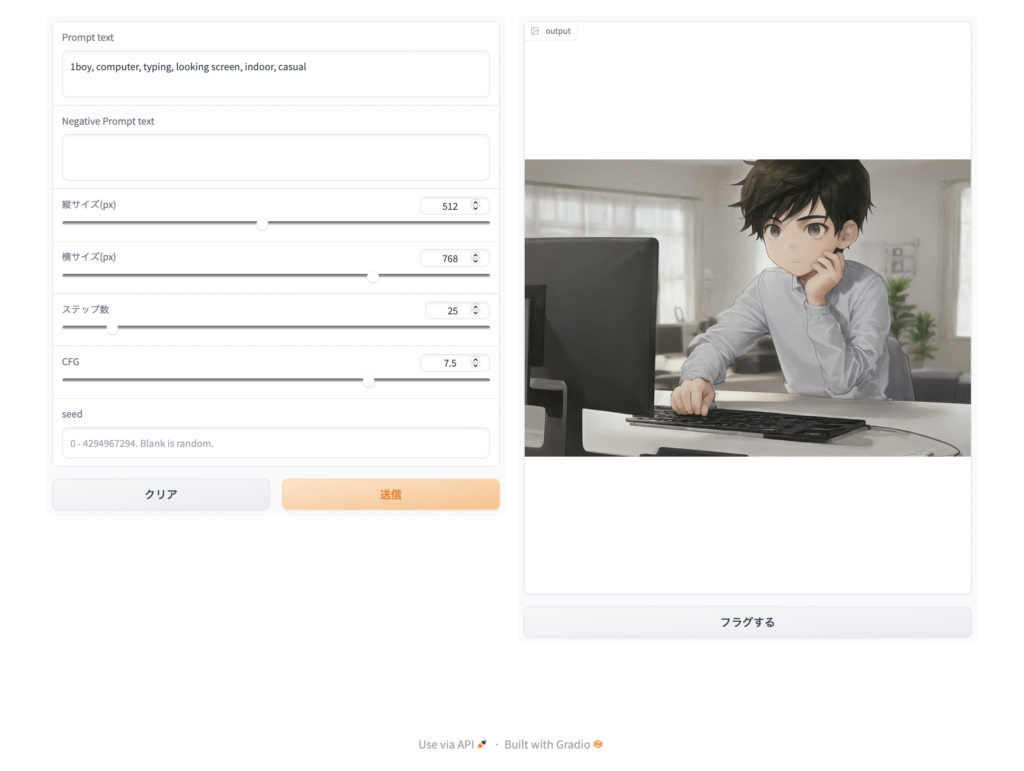
これは「1boy, computer, typing, looking screen, indoor, casual」というプロンプト(画像描画させるためのキーワード群)を指定して,横長サイズに指定した結果です。
同じ条件でも描画させる度に画像が変わるので,今回も3回目に描画させた結果を採用したものです。この辺は導入の仕方によって生成の手順は異なってくるので,1枚1枚描かせるパターンもあれば,自動的に複数枚の画像を生成させるやり方もあります。コマンドラインで済ます人もいれば,WebUIを利用することもできます。
—
導入手順は簡単で,たとえばWebUIで使いたければ…
- Python
- pythonライブラリ
- torch
- diffusers
- gradio
- 学習モデル
- Stable Diffusion v2-1
- Anything-v4.0
といったものをインストールして,pythonのスクリプトを起動するとローカルでWeb画面を開くことができます。それらはいろんな方々がネットでやり方をシェアしてくださっているので参考にしました。
ちょっと雑になりますがインストール手順はおおむね以下のような感じです。
(各自の環境によってコマンドは変わってきますので,その辺の説明はごめんなさいします。)
Macであれば,もしPythonが未導入ならHomebrewを使ってPython入れてもいいです。
brew install python@3.10あとはpipもしくはpip3でライブラリ導入:
pip3 install torchpip3 install --upgrade diffusers transformers acceleratepip3 install gradioそれから導入ツールの導入:
brew install git-lfsgit lfs install(git LFSについてはこちら)
そして学習モデルの導入:
git clone https://huggingface.co/stabilityai/stable-diffusion-2-1あるいは
git clone https://huggingface.co/andite/anything-v4.0そしたら次のpythonスクリプトをファイルに保存して動かします。(ファイル名は任意で可)
import gradio as gr
import torch
import click
import datetime
import random
from diffusers import StableDiffusionPipeline
import numpy as np
# 学習モデルを選ぶ
ai_model = "./stable-diffusion-2-1"
# ai_model = "./anything-v4.0"
def generate(prompt, nega_prom, height, width, steps, cfg, seed):
pipe = StableDiffusionPipeline.from_pretrained(
ai_model,
)
pipe.safety_checker = lambda images, **kwargs: (images, [False] * len(images))
if seed == "":
seed = int(random.randrange(4294967294))
else:
seed = int(seed)
print(f"Seed value : {seed}")
latents = torch.tensor(get_latents_from_seed(seed, width, height))
gen_img = pipe(prompt=prompt, negative_prompt=nega_prom, height=height, width=width, num_inference_steps=steps, guidance_scale=cfg, latents=latents).images[0]
gen_img.save(f"./any3_step{steps}-cfg{cfg}-{seed}.png")
return gen_img
def get_latents_from_seed(seed: int, width: int, height:int) -> np.ndarray:
# 1 is batch size
latents_shape = (1, 4, height // 8, width // 8)
# Gotta use numpy instead of torch, because torch's randn() doesn't support DML
rng = np.random.default_rng(seed)
image_latents = rng.standard_normal(latents_shape).astype(np.float32)
return image_latents
webui = gr.Interface(fn=generate,
inputs=[
gr.Textbox(label = 'Prompt text', value="", lines=2, elem_id="prompt"),
gr.Textbox(label = 'Negative Prompt text', value="", lines=2, elem_id="nega_prom"),
gr.Slider(minimum=64, maximum=1024, step=64, label="縦サイズ(px)", value=768, elem_id="height"),
gr.Slider(minimum=64, maximum=1024, step=64, label="横サイズ(px)", value=512, elem_id="width"),
gr.Slider(minimum=10, maximum=150, step=1, label="ステップ数", value=25, elem_id="steps"),
gr.Slider(minimum=1, maximum=10, step=0.5, label='CFG', value=7.5, elem_id="cfg"),
gr.Textbox(label = 'seed', value=None, placeholder="0 - 4294967294. Blank is random.", elem_id="seed"),
],
outputs=gr.Image().style(height=768)
)
webui.launch()Pythonスクリプトについて参考にしたWebページはこちら(感謝感謝)。
—
本来であれば,画像生成系AIについて整理してから書きたいところですが,それもまた別の機会に。
私自身はまだ生成系AIをどのように自分の生産活動に活かすとよいのか模索中ですが,可能性があることは嫌というほど感じているので,何かしら自分で取り組む糸口を見つけ出してみようと思います。
でも生成した画像をブログ記事のアイキャッチ画像にするのは,地味に実用的かも。